数学是自然科学的皇后,计算机的设计初衷是科学计算。计算机的最基本功能是需要存储整数、实数,及对整数和实数进行算术四则运算。
但是在计算机从业者的眼中,我们知道的数学相关的基本数据类型通常是整型、浮点型、布尔型。整型又分为int8(用8位表示的整数)、uint8(用8位表示的无符号整数)、int16、uint16、int32、uint32,浮点型又分为float16(半精度,FP16)、float32(单精度)、float64(双精度)。今天,我们就来聊聊浮点数。
#1 为什么叫浮点数?
由于实数在计算机中的表示方法是以小数点浮动的方式表示的,所以称之为浮点数。
1、计算机中的整数表示
众所周知,计算机最底层是二进制计数。用二进制数表示整数很简单(本文不考虑原码、反码、补码,也不考虑大端模式和小端模式),最高位表示符号位,0表示正数,1表示负数,余下的位表示二进制值。
int8即使用8位表示的整数,最高位用来表示正负符号,还有7位表示数字,其所能表示的范围是[-128,127]。有人可能会想,00000000表示正0,10000000表示负0,int8表示的范围岂不是[-128,127]吗?但用两个序列表示同一个数,这本身就是一种浪费。如果计算机从最底层就开始这样浪费,那还了得?所以节约资源,从我做起。
2、用定点数来表示实数
最高位表示符号,然后再约定整数占几位,余下的位都是小数。从另一个角度来说,即小数点的位置是固定的。优点是计算很方便,缺点是存储的数据范围有限。
3、用浮点数来表示实数
最高位表示符号,再约定一部分二进制位表示指数域,余下的是数域。优点是能表示的数据范围很大,缺点是计算慢。但是80286出现后,有了浮点协处理数(FPU),浮点数表示方式成为了主流。
IEEE-754是IEEE制定的二进制浮点数算术标准(IEEE即电气与电子工程师协会,这个协会制定了很多计算机领域的标准),也计算机中表示浮点数的行业标准,于1985年正式采用,2008年和2019年又分别进行了完善和修订。
题外话
我司首席科学家金耀初教授,就是现任IEEE计算智能协会主席。计算智能协会是IEEE下设的39个专业学会之一,目前是会员约9000人,是IEEE唯一以人工智能、计算智能为主要研究领域的学会。
我们以最常见的64位、32位、16位浮点数为例,如下图所示:

FP64称为双精度浮点数,一共64位,1位表示正负符号,11位表示指数,52位表示小数,可表达的精度范围是:
![]()
FP32是我们最常用的浮点数,也称为单精度浮点数,一共32位,1位表示正负符号,8位表示指数,23位表示小数,可表达的精度范围是:
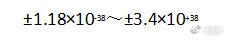
FP16称为半精度浮点数,一共16位,1位表示正负符号,5位表示指数,10位表示小数,可表达的数据范围是:
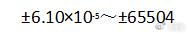
![]()
![]()
我们再以最简单的16位浮点数为例,如下图所示:
![]()
![]()
互联网上有一些很有意思的网页,能帮我们更深刻的认识到浮点数。我们挑选了由纽约市立大学计算机科学系提供的网页,网址为https://babbage.cs.qc.cuny.edu/ieee-754.old/decimal.html(或者也可以打开https://baseconvert.com/ieee-754-floating-point)。
![]()
接下来,我们随机输入一个浮点数,例如38.375,然后点击Rounded,再看看其在计算机中是如何表达的。
![]()
最高位是31位(位序从0开始),此处为0,表示是正数
接下来是指数域,从30位到23位一共是8位,最大能表示的数是256,最小能表示的数是0
指数域的值要减掉127,此处指数域是10000100,即132-127=5
余下的都是尾数域,从22位到0位一共是23位,此处是1.00110011(小数点前面的1是最终的32位数据里不存在的,因为尾数规范化后都是以1开始,所以这个1都是省略的)
最高位好理解,但是指数域5和尾数域的1.00110011是怎么得到38.375的?请各位先思考一下再看下面的计算过程。
![]()
移动数域的小数点位置,这个操作是不是浮点?我认为,这就是浮点数的由来。
接下来还有一个很有意思的问题,即浮点数的精度问题。以0.3这个数为例,我们输入0.3后,分别点击Not Rounded和Rounded(因为这里是二进制数,不适合翻译为四舍五入,所以我用原单词替代),分别得到如下两图:
Not Rounded模式下
![]()
Not Rounded模式下,数域为1 .00110011001100110011001,最终计算得到的十进制数是0.299999总是比0.3小一点点。
为什么会这样?因为十进制的有穷数0.3,转换为二进制数后是一个无穷数(1001无限循环),如果直接扔掉后面的数,那么最终转换后的十进制数据就会少了一点点,变成了0.29999999。
Rounded模式下
![]()
Rounded模式下,数域为1 .00110011001100110011010,也就是向前进了一位,这样最终得到的数变成了0.30000001,即比实际的十进制数0.3大了一点点。
所以在实际编程中,不建议对浮点数数据直接进行等值比较,一般使用区域比较,因为浮点数存在精度问题。c/c++程序员们遇到的问题0.1 + 0.2 = 0.30000000000000004也是这个原因导致的。
#2 BF16(Brain Float)
BF16是一种全新的浮点数格式,专门服务于人工智能和深度学习,最开始是Google Brain发明并应用在TPU上的,后来Intel,Arm及一众头部公司都在广泛使用。
BF16也是用16位来表示浮点数,但是是用8位表示指数,用7位表示小数,此时BF16表示的整数范围和FP32是一样的,小数部分则存在着很大的误差。
以前大部分的AI训练都使用FP32,但有相关的论文证明,在深度学习中降低数字的精度可以减少tensor相乘所带来的运算功耗,且对结果的影响却并不是非常大,且更少的尾数也使它能够拥有更小的芯片面积。因此在模型越来越大、计算越来越密集的人工智能领域,BF16也得到了广泛的应用。
#3 模型量化及INT8
从数据在计算机上的表示来看,整数运算比浮点数运算要快很多。而训练一个深度神经网络模型得到的参数通常都是FP32类型的,我们将其部署到终端NPU上时,通常需要将其量化为8位整数(即int8或者uint8)。
为什么人工神经网络模型要量化?因为终端的算力、资源都是有限的,量化后有如下好处:
减小了模型尺寸。原有的一个参数如果是32位表示的实数,量化后用8位整数来表示,这样模型能缩小至原模型大小的四分之一;
降低了内存和存储占用;
降低了功耗;
提升了计算速度。
这些特点都能有效地帮助模型部署在终端设备上,虽然量化会带来一些精度上的损失,但通过良好的量化算法和设计有效的算子,量化后的模型在终端上能够拥有接近云端模型的准确率,同时能极大节约云端算力和网络传输成本。
转载此文是出于传递更多信息目的。若来源标注错误或侵犯了您的合法权益,请与本站联系,我们将及时更正、删除、谢谢。
https://www.414w.com/read/274074.html










