现在已经有很多非常不错的语音转文本的AI应用了,比如通义听悟、飞书妙记等。不过,对于大批量、多个文件夹的语音转文本,手工操作就比较麻烦了,还是有个程序自动化运行更方面。
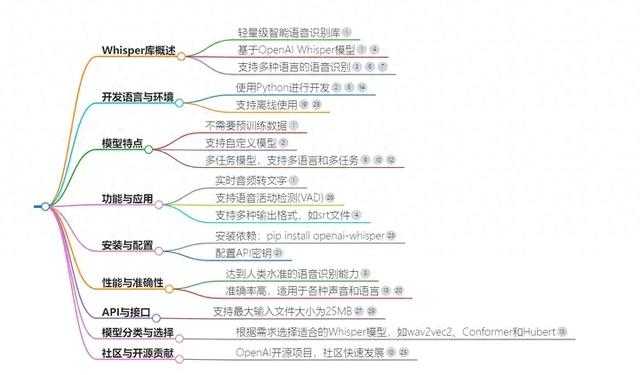
Whisper 是一个由 OpenAI 开发的开源语音识别库,旨在将音频内容转换为文本。它使用深度学习模型来识别和转录语音,支持多种语言和多种音频格式。借助这个开源免费的Whisper库,可以很方便的实现批量语音转文本。
在kimichat对话框中输入提示词:
你是一个Python编程专家,要完成一个Python脚本的编写任务,具体步骤如下:
打开文件夹:D:CHATGPT For TikTok TikTok Mastery with CHATGPT
文件夹里面有多个子文件夹,子文件夹中有mp3格式的音频,读取子文件夹中的所有音频文件;
用openai-whisper库将mp3格式音频识别为和音频同名的文本文档,然后保存在和mp3音频的同一个文件夹中;
注意:Whisper语音模型使用medium模型,要识别的音频为英文内容
下面是openai-whisper库的使用示例:
import whisper
model = whisper.load_model("medium")
result = model.transcribe("audio.mp3")
print(result["text"])
![]()
这是kimichat给出的Python源代码:
import os
import whisper
# 定义 Whisper 模型路径
MODEL_PATH = "medium" # 这里我们直接使用 "medium" 字符串,因为根据你的描述,不需要指定具体的模型文件路径
# 定义音频文件夹路径
AUDIO_FOLDER = 'D:\CHATGPT For TikTok TikTok Mastery with CHATGPT'
# 初始化 Whisper 模型
model = whisper.load_model(MODEL_PATH)
# 遍历文件夹中的所有子文件夹和文件
for root, dirs, files in os.walk(AUDIO_FOLDER):
for file in files:
# 检查文件是否为 mp3 格式
if file.endswith('.mp3'):
# 构建 mp3 文件的完整路径
mp3_path = os.path.join(root, file)
# 构建文本文件的完整路径
text_path = os.path.splitext(mp3_path)[0] + '.txt'
# 使用 Whisper 模型识别音频并生成文本
try:
result = model.transcribe(mp3_path)
# 保存文本到文件
with open(text_path, 'w', encoding='utf-8') as f:
f.write(result["text"])
print(f'Transcription saved: {text_path}')
except Exception as e:
print(f'Error transcribing audio from {mp3_path}: {e}')
print('Transcription process completed.')
由于whisper库依赖pyTorch,所以还要安装其他几个库。而这几个库由于版本兼容问题,可能会发生冲突,所以最好使用conda生成虚拟的Python环境,然后安装在这个虚拟环境中。
用conda创建一个3.9版本的Python环境:conda create n myenv python=3.9
![]()
在这个虚拟环境中安装whisper库:pip install openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
安装pytorch库:conda install pytorch torchvision torchaudio cpuonly -c pytorch
![]()
![]()
whisper 在处理音频文件时会用到 ffmpeg,也需要安装,下载地址:https://github.com/BtbN/FFmpeg-builds/releases,安装完成后,然后将ffmpeg.exe所在文件夹路径在系统环境变量设置中添加到变量Path中。
接下来,在vscode里面设置好使用这个虚拟的Python3.9版本环境:
![]()
View——command palette——select interpreter——Python3.9.19
![]()
这些都设置好之后,就可以在虚拟环境中运行Python程序了:
![]()
运行时出现一个警告:d:anacondaenvsmyenvlibsite-packageswhisper ranscribe.py:115: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
这个警告信息 UserWarning: FP16 is not supported on CPU; using FP32 instead 是由于尝试在 CPU 上使用半精度(FP16)浮点数进行计算,但 CPU 不支持 FP16 运算,因此回退到使用单精度(FP32)浮点数。
在深度学习中,FP16 可以提供更快的计算速度和减少内存使用,但需要特定的硬件支持,比如支持 FP16 运算的 GPU。如果你在 CPU 上运行代码或者 GPU 不支持 FP16,那么库会自动回退到使用 FP32,这是一个完全兼容但计算速度较慢的选项。
这个警告通常不会影响程序的运行,只是表明性能可能不是最优的。如果你希望消除这个警告,可以采取以下措施之一:
使用支持 FP16 的 GPU:如果你有支持 FP16 的 GPU,确保你的环境已经正确安装并配置了相应的驱动和库(如 CUDA 和 cuDNN)。这样,当你在 GPU 上运行代码时,就可以利用 FP16 提升性能。
忽略警告:如果你不打算使用 FP16 支持的硬件,可以选择忽略这个警告。在 Python 中,你可以使用 warnings 库来忽略特定类型的警告:
import warnings
warnings.filterignore("UserWarning", message="FP16 is not supported on CPU; using FP32 instead")
将上述代码添加到你的脚本中,可以在运行时忽略这个特定的警告信息
直接忽略这个警告就好,程序运行结果良好:
![]()
转载此文是出于传递更多信息目的。若来源标注错误或侵犯了您的合法权益,请与本站联系,我们将及时更正、删除、谢谢。
https://www.414w.com/read/549316.html









